LangGraph Human-in-the-Loop: Interrupt Patterns in Python
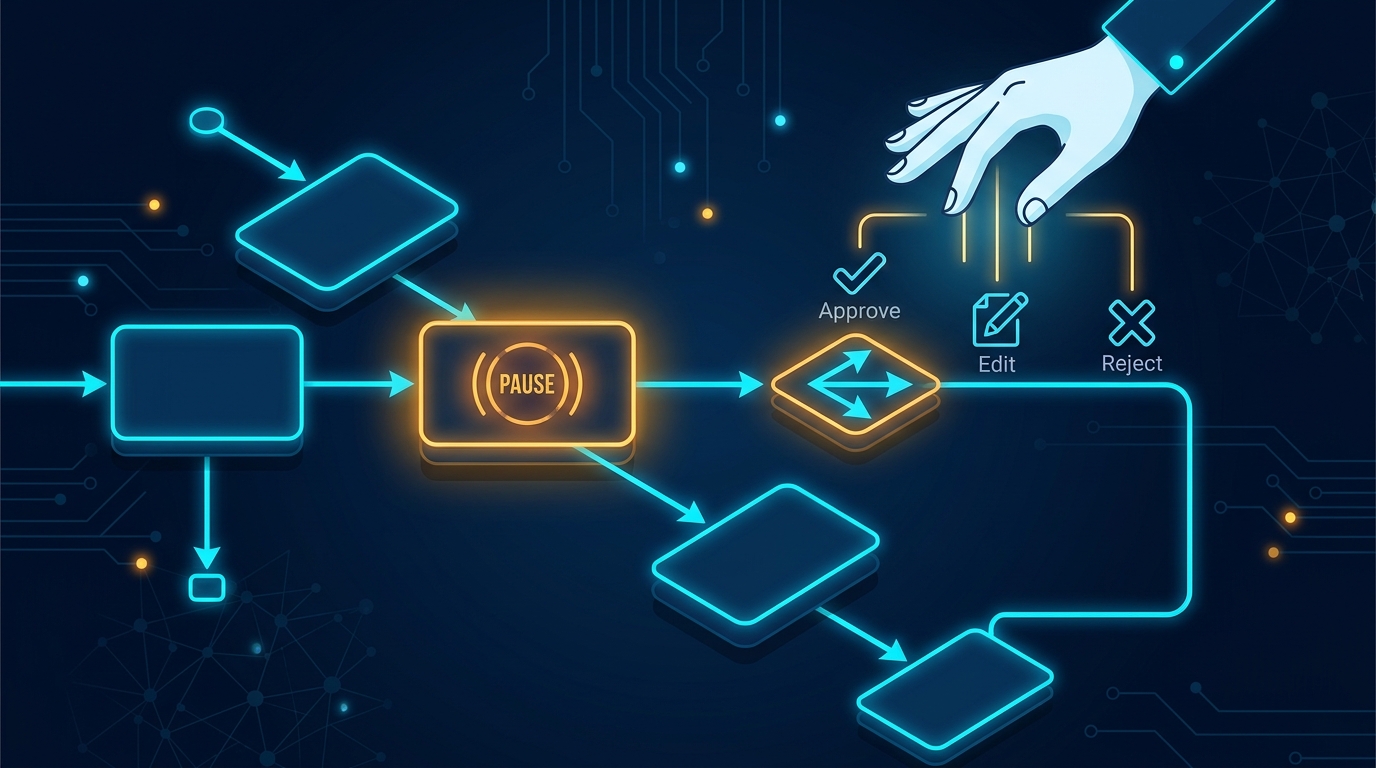
from langgraph.types import interrupt — build human-in-the-loop approval workflows in LangGraph. Step-by-step with approve, reject, and edit patterns.
LangGraph Human-in-the-Loop: Interrupt Patterns in Python
Fully autonomous agents still make mistakes — bad tool calls, hallucinated parameters, actions that should have required a second set of eyes. That’s why every production-grade agent needs a human-in-the-loop layer.
LangGraph’s interrupt() function and Command primitive give you exactly that: the ability to pause graph execution mid-flight, surface a decision to a human, and resume with their input — all while the graph’s checkpointed state is safely persisted. LangChain announced this simplified interrupt interface in December 2024, and it’s now the recommended way to build HITL agents over the older interrupt_before / interrupt_after approach. (See the LangChain announcement.)
In this tutorial, we’ll build a production-realistic agent that plans and executes actions — and pauses for human review before each one. You’ll learn three patterns: approve-as-is, reject-and-alt-route, and edit-the-proposed-action-before-executing.
Prerequisites
- Python 3.10 or higher
- An OpenAI API key (or any LangChain-compatible model)
- Basic familiarity with LangGraph’s StateGraph
Setup
mkdir langgraph-hitl && cd langgraph-hitl
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install langgraph langchain-openai python-dotenv
Create a .env file:
OPENAI_API_KEY=your-api-key-here
The Core Concept: interrupt() and Command
Before writing code, understand the two primitives:
-
interrupt(value)— called inside a node. Raises a resumable exception that halts graph execution. Thevalueis sent to whoever holds the execution handle (a CLI prompt, a web UI, an API consumer). The graph state is checkpointed automatically — nothing is lost. -
Command(resume=...)— used by the caller to resume a paused graph. The payload becomes the return value ofinterrupt()inside the node, letting the node branch based on the human’s decision.
These two primitives replace the older pattern of configuring interrupt_before / interrupt_after node names on compilation, which forced you into rigid “pause before/after every call to node X” semantics. With interrupt(), you decide exactly when and why to pause — mid-node if needed. (LangGraph Interrupts docs)
Step 1: Define the State and LLM
We’ll build an agent that takes a user request, plans a series of actions, and asks for human approval before executing each one.
import os
from dotenv import load_dotenv
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.types import interrupt, Command
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
from langchain_core.tools import tool
load_dotenv()
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
pending_tool_calls: list[dict] | None
The pending_tool_calls field tracks which tool invocations are awaiting human approval.
Step 2: Define Your Tools
These are the actions the agent wants to take. In production, these might be send_email, delete_record, or deploy_service. We’ll use simple examples.
@tool
def lookup_inventory(item: str, warehouse: str) -> str:
"""Look up an item in a warehouse inventory system."""
# In production, this would call a real API
return f"Found 42 units of '{item}' in warehouse {warehouse}"
@tool
def create_purchase_order(item: str, qty: int, vendor: str) -> str:
"""Create a purchase order for a given item."""
# In production, this would call an ERP system
return f"PO created: {qty} x '{item}' from {vendor} (PO#2026-0047)"
@tool
def send_notification(channel: str, message: str) -> str:
"""Send a notification via the specified channel."""
return f"Notification sent via {channel}: {message[:50]}..."
tools = [lookup_inventory, create_purchase_order, send_notification]
llm_with_tools = llm.bind_tools(tools)
Step 3: Build the Agent Node with interrupt()
Here’s where the HITL logic lives. The LLM receives the conversation, decides on a tool call, and then we pause — presenting the proposed tool call to a human for review.
def agent_planner(state: AgentState) -> AgentState:
"""LLM decides what tool (if any) to call next."""
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}
def human_review(state: AgentState) -> AgentState:
"""
Pauses execution and asks a human to review
the agent's proposed tool call.
"""
last_message = state["messages"][-1]
if not hasattr(last_message, "tool_calls") or not last_message.tool_calls:
# No tool calls — LLM is done, respond directly
return {"messages": []}
tool_calls = last_message.tool_calls
state["pending_tool_calls"] = tool_calls
# Present each proposed call to the human
# The interrupt() value shows in the execution stream
decision = interrupt(
{
"type": "tool_approval_request",
"tool_calls": tool_calls,
"instructions": (
"Review the proposed tool calls. "
"Reply with one of: 'approve', 'reject', "
"or 'edit:<corrected_json>'."
),
}
)
# The resume payload comes back via Command(resume=...)
return {
"messages": [],
"pending_tool_calls": tool_calls,
"_human_decision": decision, # temporary, consumed by executor
}
def tool_executor(state: AgentState) -> AgentState:
"""Executes approved tool calls — or handles rejections."""
tool_calls = state.get("pending_tool_calls") or []
decision = state.get("_human_decision", "approve")
if isinstance(decision, dict):
# Could contain structured decision data — extract it
decision = decision.get("action", "approve")
# Build the tools dictionary for lookup
tool_map = {t.name: t for t in tools}
results = []
for tc in tool_calls:
tool_name = tc["name"]
tool_args = tc["args"]
tool_id = tc["id"]
if decision == "reject":
results.append(
ToolMessage(
content="Tool call rejected by human reviewer.",
tool_call_id=tool_id,
)
)
continue
tool_fn = tool_map.get(tool_name)
if not tool_fn:
results.append(
ToolMessage(
content=f"Unknown tool: {tool_name}",
tool_call_id=tool_id,
)
)
continue
result = tool_fn.invoke(tool_args)
results.append(
ToolMessage(content=result, tool_call_id=tool_id)
)
return {
"messages": results,
"pending_tool_calls": None,
"_human_decision": None,
}
The flow is: agent_planner calls the LLM → if the LLM wants to use a tool, human_review interrupts → the human decides → tool_executor either runs or skips the call based on that decision.
Step 4: Assemble the Graph
def needs_tool_call(state: AgentState) -> str:
"""Conditional edge: does the last message contain tool calls?"""
last_message = state["messages"][-1] if state["messages"] else None
if (
last_message
and hasattr(last_message, "tool_calls")
and last_message.tool_calls
):
return "review"
return "end"
def build_hitl_graph():
graph = StateGraph(AgentState)
# Add nodes
graph.add_node("agent", agent_planner)
graph.add_node("review", human_review)
graph.add_node("execute", tool_executor)
# Define edges
graph.add_edge(START, "agent")
graph.add_conditional_edges(
"agent",
needs_tool_call,
{"review": "review", "end": END},
)
graph.add_edge("review", "execute")
graph.add_edge("execute", "agent") # loop back for multi-step chains
return graph.compile()
Step 5: Run with Checkpointing
Human-in-the-loop requires checkpointing. Without a checkpointer, the graph can’t save state when paused — so there’s nothing to resume from. We’ll use MemorySaver for development.
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
graph = build_hitl_graph()
Now invoke with a question that triggers a tool call:
from langchain_core.messages import HumanMessage
config = {"configurable": {"thread_id": "order-001"}}
# First invocation — runs until interrupt
result = graph.invoke(
{"messages": [HumanMessage(content="Check warehouse SF-01 for item 'widget-x'")]},
config,
)
This stops at the interrupt(). Inspect the pending state:
from langgraph.types import Interrupt
pending = graph.get_state(config)
interrupts = pending.pending_tasks
if interrupts:
for i in interrupts:
print(f"Interrupt #{i.id}: {i.interrupts}")
You’ll see output like:
Interrupt #...: [Interrupt(value={'type': 'tool_approval_request', 'tool_calls': [{'name': 'lookup_inventory', 'args': {'item': 'widget-x', 'warehouse': 'SF-01'}, 'id': 'call_abc123'}], 'instructions': 'Review the proposed tool calls...' })]
Step 6: Resume with a Decision
from langgraph.types import Command
config = {"configurable": {"thread_id": "order-001"}}
# Approve the tool call
result = graph.invoke(
Command(resume="approve"),
config,
)
# Print the final response
for msg in result["messages"]:
if isinstance(msg, AIMessage) and not msg.tool_calls:
print(msg.content)
The Command(resume="approve") payload flows back into the human_review node as the return value of interrupt(). The node attaches it to state, and tool_executor picks it up and runs the tool.
Here’s what each decision type looks like:
# Option 1: Approve — the tool executes as planned
graph.invoke(Command(resume="approve"), config)
# Option 2: Reject — the tool is skipped, LLM receives the rejection notice
graph.invoke(Command(resume="reject"), config)
# Option 3: Edit — modify the tool arguments before execution
graph.invoke(
Command(
resume={
"action": "edit",
"correction": {"item": "widget-x", "warehouse": "SF-02"},
}
),
config,
)
For edit decisions, you’d update the tool_executor to read the correction field:
def tool_executor_with_edits(state: AgentState) -> AgentState:
"""Executes approved tool calls, supporting human edits."""
tool_calls = state.get("pending_tool_calls") or []
decision = state.get("_human_decision", "approve")
tool_map = {t.name: t for t in tools}
results = []
for tc in tool_calls:
tool_name = tc["name"]
tool_id = tc["id"]
if isinstance(decision, dict) and decision.get("action") == "reject":
results.append(
ToolMessage(
content="Tool call rejected by human reviewer.",
tool_call_id=tool_id,
)
)
continue
# Apply human-edit corrections if provided
if isinstance(decision, dict) and decision.get("action") == "edit":
tool_args = decision.get("correction", tc["args"])
else:
tool_args = tc["args"]
tool_fn = tool_map.get(tool_name)
if not tool_fn:
results.append(
ToolMessage(
content=f"Unknown tool: {tool_name}",
tool_call_id=tool_id,
)
)
continue
result = tool_fn.invoke(tool_args)
results.append(
ToolMessage(content=result, tool_call_id=tool_id)
)
return {
"messages": results,
"pending_tool_calls": None,
"_human_decision": None,
}
Step 7: Multi-Step Approval — Chain Interrupts
The real power emerges when an agent chains through multiple tool calls, each requiring approval. Our graph already loops execute → agent, so if the LLM decides on a second tool after the first one returns, it hits human_review again.
# This triggers a chain: lookup_inventory → (approve) → LLM decides
# to also create_purchase_order → interrupt again → (approve) → done
result = graph.invoke(
{
"messages": [
HumanMessage(
content=(
"Check warehouse SF-01 for 'widget-x'. "
"If stock is below 10 units, create a PO for "
"100 units from vendor 'Acme Supply'."
)
)
]
},
{"configurable": {"thread_id": "order-002"}},
)
The agent invokes the first tool, pauses for approval, executes, reasons about the result, decides on a second tool, pauses again — and the human reviews each step independently. This is the ReAct-with-approval pattern, and it’s the safest way to deploy agents that touch production systems.
Pattern: Fine-Grained Tool-Level Interrupts
If you want to interrupt only for sensitive tools (say, send_notification but not lookup_inventory), add the decision logic in the human_review node:
SENSITIVE_TOOLS = {"send_notification", "create_purchase_order"}
def smart_review(state: AgentState) -> AgentState:
"""Only interrupt for sensitive tool calls."""
last_message = state["messages"][-1]
if not hasattr(last_message, "tool_calls") or not last_message.tool_calls:
return {"messages": []}
# Check if any tool call is sensitive
call_tool_calls = last_message.tool_calls
has_sensitive = any(
tc["name"] in SENSITIVE_TOOLS for tc in call_tool_calls
)
if not has_sensitive:
# Auto-approve safe tools
state["pending_tool_calls"] = call_tool_calls
state["_human_decision"] = "approve"
return {
"messages": [],
"pending_tool_calls": call_tool_calls,
"_human_decision": "approve",
}
# Sensitive tool — interrupt for human review
decision = interrupt(
{
"type": "sensitive_tool_approval",
"tool_calls": call_tool_calls,
"instructions": "This action requires human approval.",
}
)
return {
"messages": [],
"pending_tool_calls": call_tool_calls,
"_human_decision": decision,
}
Running This as an API
In production, you won’t use MemorySaver — you’ll use LangGraph’s server runtime or a persistent checkpointer. The LangGraph Platform provides a /threads/{thread_id}/runs endpoint that handles interrupts natively: when a run hits interrupt(), the API returns a 409 Conflict response with the interrupt payload. The client (your web UI) displays the decision prompt, collects the user’s input, and POSTs a Command(resume=...) to resume. (LangGraph Deploy docs)
# Persistent checkpointer for production
from langgraph.checkpoint.sqlite import SqliteSaver
# Or use PostgresSaver for multi-worker deployments
checkpointer = SqliteSaver.from_conn_string(":memory:")
graph = build_hitl_graph() # .compile(checkpointer=checkpointer)
The Three HITL Patterns, Summarized
| Pattern | When to use | Command(resume=...) payload |
|---|---|---|
| Approve/Reject (binary) | Sensitive actions: send email, delete data | "approve" or "reject" |
| Approve/Edit/Reject | Actions the human might tweak before running | "approve", "reject", or {"action": "edit", "correction": {...}} |
| Tool-level routing | Some tools auto-approve, others need review | Decision logic inside the review node, not the Command |
Key Takeaways
interrupt()pauses the graph from inside any node, not just between nodes. The checkpoint saves everything.Command(resume=...)is the only way to resume — its payload becomes the interrupt’s return value.- You must use a checkpointer — without one, there’s no state to resume.
- Loop your graph (
execute → agent) to support multi-step approval chains. - Tool-level routing lets you auto-approve low-risk tools while requiring review for sensitive ones.
When we deploy agents that touch production systems — ordering inventory, sending customer messages, modifying records — we never skip human-in-the-loop. The interrupt pattern gives you the audit trail, the safety net, and the ability to correct the agent mid-flight without restarting the conversation.
For a deeper look at deploying agents with HITL to production, see our Deploying AI Agents to Production guide. And if you’re new to LangGraph’s StateGraph model, start with our first LangGraph agent tutorial before layering in interrupts.
References: LangGraph Interrupts documentation, LangChain HITL announcement, LangGraph Human-in-the-Loop docs.
Related Posts

Build a Healthcare AI Agent with LangGraph: Patient Triage & Scheduling
Step-by-step LangGraph tutorial building a clinical triage agent with patient lookup, symptom assessment, appointment scheduling, and clinician escalation.
LangGraph State, Checkpointing, and Resumable Agents
Build a production-grade LangGraph agent with TypedDict state, SQLite checkpointing, and human-in-the-loop interrupts. Complete runnable code.
Build a Retail AI Agent with LangGraph: Inventory & Orders
Step-by-step LangGraph tutorial building a retail AI agent with StateGraph, tool-calling nodes for inventory lookup, order processing, and returns.