LangGraph State, Checkpointing, and Resumable Agents
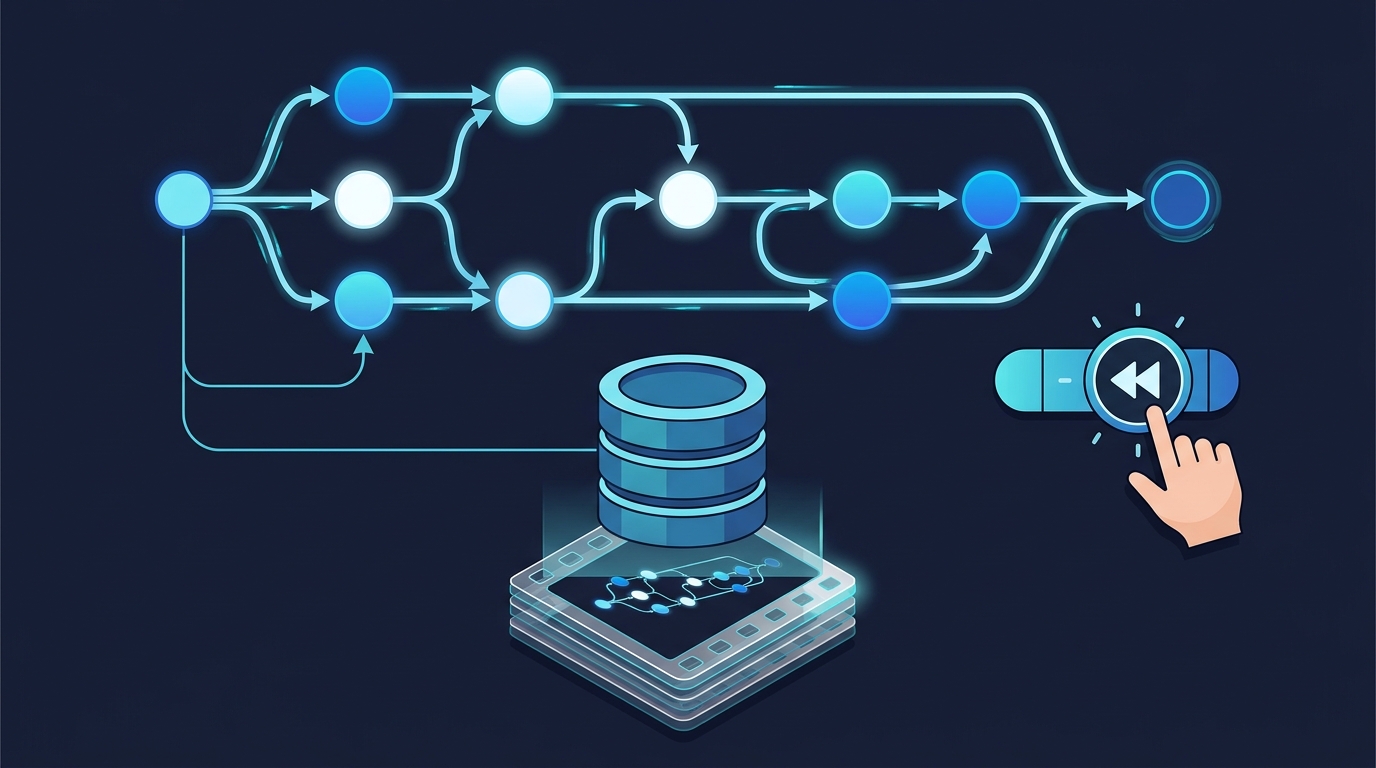
Build a production-grade LangGraph agent with TypedDict state, SQLite checkpointing, and human-in-the-loop interrupts. Complete runnable code.
Every LangGraph tutorial online shows you a toy graph: a node calls an LLM, the LLM calls a tool, done. Real production agents need three things those tutorials skip:
- Typed state so your nodes compile and don’t silently drop fields.
- Durable checkpointing so a crash mid-way doesn’t destroy a 47-step conversation.
- Resumable execution so you can interrupt, inspect state, time-travel, and continue.
We’re going to build a research agent that plans, executes tool calls, and pauses for human approval before each action — with full SQLite checkpointing, typed state, and the ability to rewind and edit past decisions. The code runs end-to-end on your machine.
Prerequisites
- Python 3.10 or higher
- An OpenAI API key (or any LangChain-compatible provider)
- ~10 minutes of your time
mkdir langgraph-persistent-agent && cd langgraph-persistent-agent
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install langgraph langchain-openai
Create a .env file with your key:
OPENAI_API_KEY=sk-your-key-here
Defining Typed State
LangGraph graphs operate on a shared state object. Using TypedDict (or LangGraph’s newer @dataclass-style State class), every node sees exactly what it needs and the type-checker catches mistakes before they hit production.
We’ll define a research agent state that tracks messages, a plan, the current step index, tool results, and optional metadata:
import uuid
import json
import datetime as dt
from typing import Annotated, TypedDict, List
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_core.messages import AIMessage, ToolMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.memory import MemorySaver
from langgraph.types import Command, interrupt
class ResearchState(TypedDict):
"""Typed state for our research agent."""
messages: Annotated[List[BaseMessage], "conversation_history"]
plan: List[str]
current_step: int
tool_results: List[str]
metadata: dict
The Annotated type on messages tells LangGraph this field is a reducer — new messages get appended to the list rather than replaced. The remaining fields use the default assignment reducer (last write wins), which is fine for plan, step, and results.
The Nodes
Our research agent has three nodes:
planner_node— generates a research plan from the user query.tool_caller_node— executes the current plan step, interrupting for approval.summarizer_node— compiles all results into a final answer.
# Simulated research tool — replace with real web-search tools in production
class SearchTool:
"""A simulated search tool for demonstration."""
name = "web_search"
description = "Search the web for information about a topic."
def search(self, query: str) -> str:
# In production, use Tavily, DuckDuckGo, or a real search API
return (
f"Search results for '{query}': "
f"The most recent findings suggest that {query} "
f"is an active area with developments in automation, "
f"machine learning integration, and open-source tooling. "
f"See https://example.com/{query.replace(' ', '-')} for details."
)
search_tool = SearchTool()
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def planner_node(state: ResearchState) -> dict:
"""Generate a research plan based on the user's query."""
print("\n[PLANNER] Generating research plan...")
plan_prompt = (
"You are a research assistant. Given a user query, "
"create a numbered research plan with 2-4 steps. "
"Respond ONLY with a JSON array of step strings. "
'Example: ["Step 1: ...", "Step 2: ..."]\n\n'
f"Query: {state['messages'][-1].content}"
)
response = model.invoke([HumanMessage(content=plan_prompt)])
plan_text = response.content.strip()
# Parse the JSON array from the response
try:
if plan_text.startswith("```"):
# Strip markdown code fences if present
plan_text = plan_text.split("```")[1]
if plan_text.startswith("json"):
plan_text = plan_text[4:]
plan = json.loads(plan_text)
except (json.JSONDecodeError, IndexError):
# Fallback: create a simple plan
plan = [
f"Search for key information about {state['messages'][-1].content}",
"Compile findings into a summary"
]
return {
"plan": plan,
"current_step": 0,
"metadata": {
"plan_created_at": dt.datetime.now().isoformat(),
**state.get("metadata", {})
}
}
def tool_caller_node(state: ResearchState) -> Command:
"""Execute the current plan step — but pause for human approval first."""
step = state["current_step"]
plan = state["plan"]
if step >= len(plan):
# No more plan steps — go to summarizer
return Command(goto="summarizer_node")
step_description = plan[step]
print(f"\n[TOOL_CALLER] Step {step + 1}/{len(plan)}: {step_description}")
# Build the tool call
search_query = state["messages"][-1].content
tool_result = search_tool.search(f"{step_description} about {search_query}")
# Build the proposed action description for human review
interrupt_question = (
f"Step {step + 1}/{len(plan)} complete.\n"
f"Plan: {step_description}\n"
f"Tool: web_search\n"
f"Query: {step_description} about {search_query}\n"
f"Result: {tool_result[:200]}...\n\n"
f"Do you approve this result? Reply 'yes' to accept, "
f"or provide a correction."
)
# PAUSE HERE — interrupts execution and waits for Command(resume=...)
resume_value = interrupt(interrupt_question)
# When we resume, resume_value contains the human's response
if isinstance(resume_value, str) and resume_value.lower().strip() != "yes":
# Human provided a correction — incorporate it
tool_result += f"\n\n[Human correction]: {resume_value}"
return Command(
update={
"tool_results": state["tool_results"] + [tool_result],
"current_step": step + 1,
"messages": state["messages"] + [
AIMessage(content=f"Completed step {step + 1}: {step_description}"),
ToolMessage(content=tool_result, tool_call_id=str(uuid.uuid4())),
],
},
goto="tool_caller_node" # Loop back for the next step
)
def summarizer_node(state: ResearchState) -> dict:
"""Compile all tool results into a final answer."""
print("\n[SUMMARIZER] Compiling final research summary...")
results_text = "\n\n".join(
f"Step {i + 1}: {r}" for i, r in enumerate(state["tool_results"])
)
summary_prompt = (
"You are a research assistant. Based on the following research results, "
"write a comprehensive summary answering the user's original question.\n\n"
f"Original query: {state['messages'][0].content}\n\n"
f"Results:\n{results_text}\n\n"
"Write a well-structured summary with key findings."
)
response = model.invoke([HumanMessage(content=summary_prompt)])
return {
"messages": state["messages"] + [AIMessage(content=response.content)],
}
Building the Graph
With nodes defined, assembling the StateGraph is straightforward. The tool_caller_node returns Command(goto=...) to decide where execution goes next, so we don’t need a separate conditional edge for it.
def build_research_graph(checkpointer=None) -> StateGraph:
"""Construct and compile the research agent graph."""
graph = StateGraph(ResearchState)
# Add nodes
graph.add_node("planner_node", planner_node)
graph.add_node("tool_caller_node", tool_caller_node)
graph.add_node("summarizer_node", summarizer_node)
# Define entry point and edges
graph.set_entry_point("planner_node")
graph.add_edge("planner_node", "tool_caller_node")
# tool_caller_node uses Command(goto=...) to self-loop or go to summarizer
graph.add_edge("summarizer_node", END)
return graph.compile(checkpointer=checkpointer)
Running with an In-Memory Checkpointer
Let’s start with the simplest setup: MemorySaver. This stores checkpoints in RAM — fine for prototyping, disastrous for production.
# Run the agent
memory_checkpointer = MemorySaver()
app = build_research_graph(checkpointer=memory_checkpointer)
# Every execution gets a unique thread ID for isolation
thread_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}
# Seed the conversation
user_query = "What are the main trade-offs between vLLM and SGLang for LLM inference?"
inputs = {
"messages": [HumanMessage(content=user_query)],
"plan": [],
"current_step": 0,
"tool_results": [],
"metadata": {"query": user_query}
}
print(f"=== Starting research thread {thread_id[:8]} ===")
# First invocation: runs planner → tool_caller_node → INTERRUPTS
for event in app.stream(inputs, config, stream_mode="updates"):
for node_name, update in event.items():
print(f"\n>>> Completed: {node_name}")
# Check what interrupts we have
state = app.get_state(config)
interrupts = state.tasks
if interrupts:
print("\n" + "=" * 50)
print(f"INTERRUPT: {interrupts[0].interrupts}")
print("=" * 50)
When you run this, you’ll see the graph execute the planner, run the first tool step, and interrupt — surfacing the action for human review.
Resume with Command
After the interrupt, we resume by invoking the graph with a Command(resume=...) value:
# Resume with approval
approval_response = "yes"
print(f"\n[RESUME] Approving with: {approval_response}")
for event in app.stream(
Command(resume=approval_response),
config,
stream_mode="updates"
):
for node_name, update in event.items():
print(f"\n>>> Completed: {node_name}")
# After processing all steps, the summarizer produces the final answer
final_state = app.get_state(config)
messages = final_state.values.get("messages", [])
for msg in messages:
if isinstance(msg, AIMessage) and not msg.tool_calls:
print(f"\n{'=' * 50}")
print(f"FINAL RESPONSE:\n{msg.content}")
print(f"{'=' * 50}")
break
The flow is:
- Planner generates the research plan
- Tool caller executes step 1 and interrupts
- We resume with
Command(resume="yes") - Tool caller loops through remaining steps, interrupting each one
- Once all steps are complete, the summarizer compiles the final answer
Interactive Run Loop
In production, you’ll want a proper loop that keeps resuming until the graph reaches END. Here’s the pattern:
def run_agent():
app = build_research_graph(checkpointer=MemorySaver())
thread_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}
inputs = {
"messages": [HumanMessage(
content="What are the trade-offs between vLLM and SGLang?"
)],
"plan": [],
"current_step": 0,
"tool_results": [],
"metadata": {},
}
while True:
# Stream until interrupt or END
for event in app.stream(inputs, config, stream_mode="values"):
pass
inputs = None # Don't resend original inputs on resume
# Check for interrupts
current_state = app.get_state(config)
if current_state.tasks and current_state.tasks[0].interrupts:
question = current_state.tasks[0].interrupts[0]
print(f"\n{question}")
response = input("Your response: ")
inputs = Command(resume=response)
else:
break
# Print final answer
final_state = app.get_state(config)
for msg in final_state.values["messages"]:
if isinstance(msg, AIMessage) and not msg.tool_calls:
print(f"\n{'=' * 50}")
print(msg.content)
print(f"{'=' * 50}")
Switching to SQLite Checkpointing
The MemorySaver vanishes when the process exits. For any real workload, you need durable persistence. LangGraph ships with a SQLite checkpointer that writes every checkpoint to a file — zero infrastructure, perfect for single-node deployments.
from langgraph.checkpoint.sqlite import SqliteSaver
import sqlite3
# Create the SQLite connection and pass it to SqliteSaver
with sqlite3.connect("agent_checkpoints.db", check_same_thread=False) as conn:
with SqliteSaver(conn=conn) as sql_checkpointer:
app = build_research_graph(checkpointer=sql_checkpointer)
# Run exactly as before — checkpoints survive process restarts
thread_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}
inputs = {
"messages": [HumanMessage(
content="Compare RAG vs fine-tuning for domain adaptation"
)],
"plan": [],
"current_step": 0,
"tool_results": [],
"metadata": {}
}
for event in app.stream(inputs, config, stream_mode="updates"):
for node_name, update in event.items():
print(f"Completed: {node_name}")
The key difference: after your Python process exits, agent_checkpoints.db on disk contains every checkpoint. Restart the process with the same thread_id and the agent resumes exactly where it left off.
For interactive resume with SQLite, wrap the same run_agent function from above, but pass a SqliteSaver checkpointer instead of MemorySaver.
Time-Travel: Rewinding and Editing State
One of LangGraph’s most powerful features is time-travel — the ability to rewind to any checkpoint, modify state, and rerun from that point. This is invaluable for debugging agent behavior and correcting bad decisions without restarting from scratch.
def time_travel_example():
"""Demonstrate time-travel: rewind, edit, and rerun."""
memory = MemorySaver()
app = build_research_graph(checkpointer=memory)
thread_id = "tt-demo-thread-001"
config = {"configurable": {"thread_id": thread_id}}
# Run the graph to the first interrupt
inputs = {
"messages": [HumanMessage(
content="Research quantum computing advances in 2026"
)],
"plan": [],
"current_step": 0,
"tool_results": [],
"metadata": {}
}
for event in app.stream(inputs, config, stream_mode="updates"):
pass
# Walk through all checkpoint snapshots for this thread
history = list(app.get_state_history(config))
print(f"\nFound {len(history)} checkpoint(s) for this thread")
for snapshot in reversed(history):
step = snapshot.values.get("current_step", "N/A")
print(f" Checkpoint: {snapshot.checkpoint['id']} step={step}")
# Find the checkpoint right after the planner ran
# (has a plan but no tool results yet)
target = next(
s for s in app.get_state_history(config)
if s.values.get("plan") and not s.values.get("tool_results")
)
# Fork from this checkpoint with a modified plan
fork_config = {
"configurable": {
"thread_id": thread_id + "_fork",
"checkpoint_id": target.checkpoint["id"],
}
}
# Inject additional plan steps
existing_plan = target.values["plan"]
modified_inputs = {
**target.values,
"plan": existing_plan + ["Additional: Check arXiv for recent papers"]
}
print(f"\nOriginal plan: {existing_plan}")
print(f"Modified plan: {modified_inputs['plan']}")
# Re-run from the fork point
for event in app.stream(None, fork_config, stream_mode="updates"):
for node_name, update in event.items():
print(f" Fork node: {node_name}")
time_travel_example()
In this example we:
- Run the graph until it interrupts.
- Walk through
get_state_historyto find the checkpoint we want. - Create a fork config pointing to that
checkpoint_id. - Inject additional plan steps and re-run from that fork.
The original thread is untouched — we’ve created a parallel branch from the same checkpoint. This is how you debug agent behavior without destroying the original execution.
Internal State Structure
For debugging, here’s what a checkpoint snapshot looks like after the planner runs:
state = app.get_state(config)
print(state.values)
# {
# "messages": [
# HumanMessage(content="Research X"),
# AIMessage(content="Step 1: Search... Step 2: Analyze...")
# ],
# "plan": ["Search...", "Analyze..."],
# "current_step": 0,
# "tool_results": [],
# "metadata": {"plan_created_at": "2026-05-12T09:00:00"}
# }
Each checkpoint captures the full state at that moment, not just the delta. This is what makes time-travel possible — you’re restoring from a complete snapshot, then replaying from there.
When to Use Which Checkpointer
Not every project needs SQLite. Here’s our recommendation based on deployment scale:
- Prototyping / colab notebooks:
MemorySaver— zero setup, loses state on exit. - Single-process deployments (sidecar, single container):
SqliteSaver— file-based, no external dependencies, ACID-compliant. Install withpip install langgraph-checkpoint-sqlite. - Multi-process / scaled deployments:
PostgresSaver(fromlanggraph-checkpoint-postgres) — shared state across replicas, required when multiple workers handle the same thread. - Managed LangGraph platform: The LangGraph server API handles checkpointing for you with built-in thread and state management (LangGraph persistent memory docs).
Complete Runnable File
All six pieces fit together into a single file. Save this as agent.py:
# agent.py — complete production-ready LangGraph agent
import uuid
import json
import datetime as dt
from typing import Annotated, TypedDict, List
from langchain_core.messages import (
BaseMessage, HumanMessage, AIMessage, ToolMessage
)
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.memory import MemorySaver
from langgraph.types import Command, interrupt
class ResearchState(TypedDict):
"""Typed state for the research agent."""
messages: Annotated[List[BaseMessage], "conversation_history"]
plan: List[str]
current_step: int
tool_results: List[str]
metadata: dict
# -- Simulated search tool ------------------------------------------
class SearchTool:
"""Replace with Tavily, DuckDuckGo, or a real search API."""
name = "web_search"
description = "Search the web for information."
def search(self, query: str) -> str:
return (
f"Results for '{query}': active developments in {query}."
)
search_tool = SearchTool()
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# -- Nodes ----------------------------------------------------------
def planner_node(state: ResearchState) -> dict:
prompt = (
"You are a research assistant. Create a research plan "
"as a JSON array. Query: " + state["messages"][-1].content
)
response = model.invoke([HumanMessage(content=prompt)])
try:
text = response.content.strip()
if text.startswith("```"):
text = text.split("```")[1].lstrip("json").strip()
plan = json.loads(text)
except (json.JSONDecodeError, IndexError):
plan = ["Search for relevant information", "Compile findings"]
return {
"plan": plan,
"current_step": 0,
"metadata": {"plan_at": dt.datetime.now().isoformat()},
}
def tool_caller_node(state: ResearchState) -> Command:
step = state["current_step"]
plan = state["plan"]
if step >= len(plan):
return Command(goto="summarizer_node")
query = state["messages"][-1].content
result = search_tool.search(f"{plan[step]} about {query}")
question = (
f"Step {step + 1}: {plan[step]}\nResult: {result[:200]}\n\n"
f"Approve? Reply 'yes' or provide a correction."
)
resume_value = interrupt(question)
if isinstance(resume_value, str) and resume_value.strip().lower() != "yes":
result += f"\n[Human correction: {resume_value}]"
return Command(
update={
"tool_results": state["tool_results"] + [result],
"current_step": step + 1,
"messages": state["messages"] + [
AIMessage(content=f"Done step {step + 1}"),
ToolMessage(content=result, tool_call_id=str(uuid.uuid4())),
],
},
goto="tool_caller_node",
)
def summarizer_node(state: ResearchState) -> dict:
results = "\n\n".join(
f"Step {i + 1}: {r}" for i, r in enumerate(state["tool_results"])
)
prompt = (
f"Original query: {state['messages'][0].content}\n\n"
f"Results: {results}\n\n"
"Write a summary."
)
response = model.invoke([HumanMessage(content=prompt)])
return {
"messages": state["messages"] + [AIMessage(content=response.content)]
}
# -- Graph ----------------------------------------------------------
def build_app():
graph = StateGraph(ResearchState)
graph.add_node("planner_node", planner_node)
graph.add_node("tool_caller_node", tool_caller_node)
graph.add_node("summarizer_node", summarizer_node)
graph.set_entry_point("planner_node")
graph.add_edge("planner_node", "tool_caller_node")
graph.add_edge("summarizer_node", END)
return graph.compile(checkpointer=MemorySaver())
# -- Run loop -------------------------------------------------------
def run_agent():
app = build_app()
thread_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}
inputs = {
"messages": [HumanMessage(
content="What are the trade-offs between vLLM and SGLang?"
)],
"plan": [],
"current_step": 0,
"tool_results": [],
"metadata": {},
}
while True:
# Stream until interrupt or END
for event in app.stream(inputs, config, stream_mode="values"):
pass
inputs = None # Don't resend original inputs on resume
# Check for interrupts
current_state = app.get_state(config)
if current_state.tasks and current_state.tasks[0].interrupts:
question = current_state.tasks[0].interrupts[0]
print(f"\n{question}")
response = input("Your response: ")
inputs = Command(resume=response)
else:
break
# Print final answer
final_state = app.get_state(config)
for msg in final_state.values["messages"]:
if isinstance(msg, AIMessage) and not msg.tool_calls:
print(f"\n{'=' * 50}")
print(msg.content)
print(f"{'=' * 50}")
if __name__ == "__main__":
run_agent()
Run it with python agent.py. The agent plans, executes each step, pauses for your approval, and delivers a researched summary. To upgrade to SQLite persistence, swap MemorySaver() for SqliteSaver(conn=sqlite3.connect("checkpoints.db")) in the build_app function.
The same graph compiles with any LangGraph checkpointer — MemorySaver, SqliteSaver, PostgresSaver, or the cloud platform’s built-in persistence. See our post on the agent durability gap for why checkpointing is table stakes for production agents.
Next Steps
Once your graph is checkpointed and resumable, the next questions are:
- Evaluation — How do you know your agent gives good answers? Read our agent evaluation guide for testing frameworks and regression testing patterns.
- Observability — Trace every node, every interrupt, every resume. Tracing LLM apps with OpenTelemetry covers the full pipeline.
- Deployment — Getting this behind a production API means handling concurrent threads, connection pooling for the checkpointer, and graceful process shutdowns. Our deployment guide walks through the full stack.
The code above is your foundation. Build on it.
Related Posts
Build a Retail AI Agent with LangGraph: Inventory & Orders
Step-by-step LangGraph tutorial building a retail AI agent with StateGraph, tool-calling nodes for inventory lookup, order processing, and returns.
LangGraph Human-in-the-Loop: Interrupt Patterns in Python
from langgraph.types import interrupt — build human-in-the-loop approval workflows in LangGraph. Step-by-step with approve, reject, and edit patterns.

LangGraph Tutorial: Build Your First AI Agent in Python
Step-by-step LangGraph tutorial. Build your first Python AI agent with StateGraph nodes, edges, and tool calls. Complete runnable code included.